Train the network
Top
Training the weights and biases of the network.
Questions to David Rotermund
An example setup
Network
Note: Okay, I forgot the full layer somehow but it is still at 99%.
import torch
# Some parameters
input_number_of_channel: int = 1
input_dim_x: int = 24
input_dim_y: int = 24
number_of_output_channels_conv1: int = 32
number_of_output_channels_conv2: int = 64
number_of_output_channels_flatten1: int = 576
number_of_output_channels_full1: int = 10
kernel_size_conv1: tuple[int, int] = (5, 5)
kernel_size_pool1: tuple[int, int] = (2, 2)
kernel_size_conv2: tuple[int, int] = (5, 5)
kernel_size_pool2: tuple[int, int] = (2, 2)
stride_conv1: tuple[int, int] = (1, 1)
stride_pool1: tuple[int, int] = (2, 2)
stride_conv2: tuple[int, int] = (1, 1)
stride_pool2: tuple[int, int] = (2, 2)
padding_conv1: int = 0
padding_pool1: int = 0
padding_conv2: int = 0
padding_pool2: int = 0
network = torch.nn.Sequential(
torch.nn.Conv2d(
in_channels=input_number_of_channel,
out_channels=number_of_output_channels_conv1,
kernel_size=kernel_size_conv1,
stride=stride_conv1,
padding=padding_conv1,
),
torch.nn.ReLU(),
torch.nn.MaxPool2d(
kernel_size=kernel_size_pool1, stride=stride_pool1, padding=padding_pool1
),
torch.nn.Conv2d(
in_channels=number_of_output_channels_conv1,
out_channels=number_of_output_channels_conv2,
kernel_size=kernel_size_conv2,
stride=stride_conv2,
padding=padding_conv2,
),
torch.nn.ReLU(),
torch.nn.MaxPool2d(
kernel_size=kernel_size_pool2, stride=stride_pool2, padding=padding_pool2
),
torch.nn.Flatten(
start_dim=1,
),
torch.nn.Linear(
in_features=number_of_output_channels_flatten1,
out_features=number_of_output_channels_full1,
bias=True,
),
torch.nn.Softmax(dim=1),
)
Data augmentation
import torchvision
test_processing_chain = torchvision.transforms.Compose(
transforms=[torchvision.transforms.CenterCrop((24, 24))],
)
train_processing_chain = torchvision.transforms.Compose(
transforms=[torchvision.transforms.RandomCrop((24, 24))],
)
Data interfacing
import torch
import numpy as np
class MyDataset(torch.utils.data.Dataset):
# Initialize
def __init__(self, train: bool = False) -> None:
super(MyDataset, self).__init__()
if train is True:
self.pattern_storage: np.ndarray = np.load("train_pattern_storage.npy")
self.label_storage: np.ndarray = np.load("train_label_storage.npy")
else:
self.pattern_storage = np.load("test_pattern_storage.npy")
self.label_storage = np.load("test_label_storage.npy")
self.pattern_storage = self.pattern_storage.astype(np.float32)
self.pattern_storage /= np.max(self.pattern_storage)
# How many pattern are there?
self.number_of_pattern: int = self.label_storage.shape[0]
def __len__(self) -> int:
return self.number_of_pattern
# Get one pattern at position index
def __getitem__(self, index: int) -> tuple[torch.Tensor, int]:
image = torch.tensor(self.pattern_storage[index, np.newaxis, :, :])
target = int(self.label_storage[index])
return image, target
Data loader
dataset_train = MyDataset(train=True)
dataset_test = MyDataset(train=False)
batch_size_train = 100
batch_size_test = 100
train_data_load = torch.utils.data.DataLoader(
dataset_train, batch_size=batch_size_train, shuffle=True
)
test_data_load = torch.utils.data.DataLoader(
dataset_test, batch_size=batch_size_test, shuffle=False
)
and you need the data from here
What makes it learn?
Optimizer Algorithms
This is just a small selection of optimizers (i.e. the algorithm that learns the weights based on a loss). Nevertheless, typically Adam or SGD will be the first algorithm you will try.
| Adagrad | Implements Adagrad algorithm. |
| Adam | Implements Adam algorithm. |
| ASGD | Implements Averaged Stochastic Gradient Descent. |
| RMSprop | Implements RMSprop algorithm. |
| Rprop | Implements the resilient backpropagation algorithm. |
| SGD | Implements stochastic gradient descent (optionally with momentum). |
Learning rate scheduler
“torch.optim.lr_scheduler provides several methods to adjust the learning rate based on the number of epochs.”
Why do you want to reduce the learning rate: Well, typically you want to start with a large learning rate for jumping over local minima but later you want to anneal the learning rate because otherwise the optimizer will jump over / oscillate around the minima.
A non-representative selection is
| lr_scheduler.StepLR | Decays the learning rate of each parameter group by gamma every step_size epochs. |
| lr_scheduler.MultiStepLR | Decays the learning rate of each parameter group by gamma once the number of epoch reaches one of the milestones. |
| lr_scheduler.ConstantLR | Decays the learning rate of each parameter group by a small constant factor until the number of epoch reaches a pre-defined milestone: total_iters. |
| lr_scheduler.LinearLR | Decays the learning rate of each parameter group by linearly changing small multiplicative factor until the number of epoch reaches a pre-defined milestone: total_iters. |
| lr_scheduler.ExponentialLR | Decays the learning rate of each parameter group by gamma every epoch. |
| lr_scheduler.ReduceLROnPlateau | Reduce learning rate when a metric has stopped improving. |
However, typically I only use lr_scheduler.ReduceLROnPlateau.
Tensorboard
We want to monitor our progress and will use Tensorboard for this.
In the beginning we need to open a Tensorboard session
import os
os.environ["TF_CPP_MIN_LOG_LEVEL"] = "3"
from torch.utils.tensorboard import SummaryWriter
tb = SummaryWriter()
Afterwards we need to close the Tensorboard session again
tb.close()
During learning we can flush the information. This allows us to observer the development in parallel in the viewer (a viewer that is build into VS code I might add…).
tb.flush()
We can add histograms for e.g. weights
tb.add_histogram("LABEL OF THE VARIABLE", VARIABLE, LEARNING_STEP_NUMBER)
or add scalars (e.g. performances or loss values)
tb.add_scalar("LABEL OF THE VARIABLE", VARIABLE, LEARNING_STEP_NUMBER)
We can also add images, matplotlib figures, videos, audio, text, graph data, and other stuff. Just because we can doesn’t mean that we want to…
We can use the event_accumulator to retrieve the stored information.
- acc = event_accumulator.EventAccumulator(PATH)
- acc.Tags() : Return all tags found as a dictionary (e.g. acc.Tags()[‘scalars’] and acc.Tags()[‘histograms’]).
- acc.Scalars(tag) : Given a summary tag, return all associated
ScalarEvents. - acc.Graph() : Return the graph definition, if there is one.
- acc.MetaGraph() : Return the metagraph definition, if there is one.
- acc.Histograms(tag) : Given a summary tag, return all associated histograms.
- acc.CompressedHistograms(tag) : Given a summary tag, return all associated compressed histograms.
- acc.Images(tag) : Given a summary tag, return all associated images.
- acc.Audio(tag) : Given a summary tag, return all associated audio.
- acc.Tensors(tag) : Given a summary tag, return all associated tensors.
Here as an example:
import os
os.environ["TF_CPP_MIN_LOG_LEVEL"] = "3"
import matplotlib.pyplot as plt
from tensorboard.backend.event_processing import event_accumulator
import numpy as np
path: str = "run"
acc = event_accumulator.EventAccumulator(path)
acc.Reload()
available_scalar = acc.Tags()["scalars"]
available_histograms = acc.Tags()["histograms"]
print("Available Scalars:")
print(available_scalar)
print()
print("Available Histograms:")
print(available_histograms)
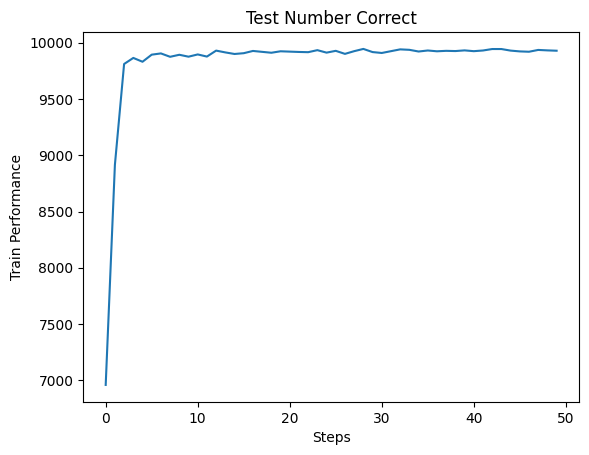
which_scalar = "Test Number Correct"
te = acc.Scalars(which_scalar)
np_temp = np.zeros((len(te), 2))
for id in range(0, len(te)):
np_temp[id, 0] = te[id].step
np_temp[id, 1] = te[id].value
print(np_temp)
plt.plot(np_temp[:, 0], np_temp[:, 1])
plt.xlabel("Steps")
plt.ylabel("Train Performance")
plt.title(which_scalar)
plt.show()
MNIST with Adam, ReduceLROnPlateau, cross-entropy on CPU
Operations you will see that are not explained yet:
| network.train() | “Sets the module in training mode.” |
| optimizer.zero_grad() | “Sets the gradients of all optimized torch.Tensors to zero.” For every mini batch we (need to) clean the gradient which is used for training the parameters. |
| optimizer.step() | “Performs a single optimization step (parameter update).” |
| loss.backward() | “Computes the gradient of current tensor w.r.t. graph leaves.” |
| lr_scheduler.step(train_loss) | After an epoch the learning rate (might be) changed. For other Learning rate scheduler .step() might have no parameter. |
| network.eval() | “Sets the module in evaluation mode.” |
| with torch.no_grad(): | “Context-manager that disabled gradient calculation.” |
import os
os.environ["TF_CPP_MIN_LOG_LEVEL"] = "3"
import torch
import torchvision # type:ignore
import numpy as np
import time
from torch.utils.tensorboard import SummaryWriter
class MyDataset(torch.utils.data.Dataset):
# Initialize
def __init__(self, train: bool = False) -> None:
super(MyDataset, self).__init__()
if train is True:
self.pattern_storage: np.ndarray = np.load("train_pattern_storage.npy")
self.label_storage: np.ndarray = np.load("train_label_storage.npy")
else:
self.pattern_storage = np.load("test_pattern_storage.npy")
self.label_storage = np.load("test_label_storage.npy")
self.pattern_storage = self.pattern_storage.astype(np.float32)
self.pattern_storage /= np.max(self.pattern_storage)
# How many pattern are there?
self.number_of_pattern: int = self.label_storage.shape[0]
def __len__(self) -> int:
return self.number_of_pattern
# Get one pattern at position index
def __getitem__(self, index: int) -> tuple[torch.Tensor, int]:
image = torch.tensor(self.pattern_storage[index, np.newaxis, :, :])
target = int(self.label_storage[index])
return image, target
# Some parameters
input_number_of_channel: int = 1
input_dim_x: int = 24
input_dim_y: int = 24
number_of_output_channels_conv1: int = 32
number_of_output_channels_conv2: int = 64
number_of_output_channels_flatten1: int = 576
number_of_output_channels_full1: int = 10
kernel_size_conv1: tuple[int, int] = (5, 5)
kernel_size_pool1: tuple[int, int] = (2, 2)
kernel_size_conv2: tuple[int, int] = (5, 5)
kernel_size_pool2: tuple[int, int] = (2, 2)
stride_conv1: tuple[int, int] = (1, 1)
stride_pool1: tuple[int, int] = (2, 2)
stride_conv2: tuple[int, int] = (1, 1)
stride_pool2: tuple[int, int] = (2, 2)
padding_conv1: int = 0
padding_pool1: int = 0
padding_conv2: int = 0
padding_pool2: int = 0
network = torch.nn.Sequential(
torch.nn.Conv2d(
in_channels=input_number_of_channel,
out_channels=number_of_output_channels_conv1,
kernel_size=kernel_size_conv1,
stride=stride_conv1,
padding=padding_conv1,
),
torch.nn.ReLU(),
torch.nn.MaxPool2d(
kernel_size=kernel_size_pool1, stride=stride_pool1, padding=padding_pool1
),
torch.nn.Conv2d(
in_channels=number_of_output_channels_conv1,
out_channels=number_of_output_channels_conv2,
kernel_size=kernel_size_conv2,
stride=stride_conv2,
padding=padding_conv2,
),
torch.nn.ReLU(),
torch.nn.MaxPool2d(
kernel_size=kernel_size_pool2, stride=stride_pool2, padding=padding_pool2
),
torch.nn.Flatten(
start_dim=1,
),
torch.nn.Linear(
in_features=number_of_output_channels_flatten1,
out_features=number_of_output_channels_full1,
bias=True,
),
torch.nn.Softmax(dim=1),
)
test_processing_chain = torchvision.transforms.Compose(
transforms=[torchvision.transforms.CenterCrop((24, 24))],
)
train_processing_chain = torchvision.transforms.Compose(
transforms=[torchvision.transforms.RandomCrop((24, 24))],
)
dataset_train = MyDataset(train=True)
dataset_test = MyDataset(train=False)
batch_size_train = 100
batch_size_test = 100
train_data_load = torch.utils.data.DataLoader(
dataset_train, batch_size=batch_size_train, shuffle=True
)
test_data_load = torch.utils.data.DataLoader(
dataset_test, batch_size=batch_size_test, shuffle=False
)
# -------------------------------------------
# The optimizer
optimizer = torch.optim.Adam(network.parameters(), lr=0.001)
# The LR Scheduler
lr_scheduler = torch.optim.lr_scheduler.ReduceLROnPlateau(optimizer)
number_of_test_pattern: int = dataset_test.__len__()
number_of_train_pattern: int = dataset_train.__len__()
number_of_epoch: int = 50
tb = SummaryWriter(log_dir="run")
loss_function = torch.nn.CrossEntropyLoss()
for epoch_id in range(0, number_of_epoch):
print(f"Epoch: {epoch_id}")
t_start: float = time.perf_counter()
train_loss: float = 0.0
train_correct: int = 0
train_number: int = 0
test_correct: int = 0
test_number: int = 0
# Switch the network into training mode
network.train()
# This runs in total for one epoch split up into mini-batches
for image, target in train_data_load:
# Clean the gradient
optimizer.zero_grad()
output = network(train_processing_chain(image))
loss = loss_function(output, target)
train_loss += loss.item()
train_correct += (output.argmax(dim=1) == target).sum().numpy()
train_number += target.shape[0]
# Calculate backprop
loss.backward()
# Update the parameter
optimizer.step()
# Update the learning rate
lr_scheduler.step(train_loss)
t_training: float = time.perf_counter()
# Switch the network into evalution mode
network.eval()
with torch.no_grad():
for image, target in test_data_load:
output = network(test_processing_chain(image))
test_correct += (output.argmax(dim=1) == target).sum().numpy()
test_number += target.shape[0]
t_testing = time.perf_counter()
perfomance_test_correct: float = 100.0 * test_correct / test_number
perfomance_train_correct: float = 100.0 * train_correct / train_number
tb.add_scalar("Train Loss", train_loss, epoch_id)
tb.add_scalar("Train Number Correct", train_correct, epoch_id)
tb.add_scalar("Test Number Correct", test_correct, epoch_id)
print(f"Training: Loss={train_loss:.5f} Correct={perfomance_train_correct:.2f}%")
print(f"Testing: Correct={perfomance_test_correct:.2f}%")
print(
f"Time: Training={(t_training-t_start):.1f}sec, Testing={(t_testing-t_training):.1f}sec"
)
torch.save(network, "Model_MNIST_A_" + str(epoch_id) + ".pt")
print()
tb.flush()
tb.close()
Output:
Epoch: 0
Training: Loss=1029.10439 Correct=75.78%
Testing: Correct=88.61%
Time: Training=8.6sec, Testing=0.6sec
Epoch: 1
Training: Loss=959.81828 Correct=86.48%
Testing: Correct=89.26%
Time: Training=8.1sec, Testing=0.5sec
[...]
Epoch: 48
Training: Loss=881.60049 Correct=99.20%
Testing: Correct=99.04%
Time: Training=9.2sec, Testing=0.5sec
Epoch: 49
Training: Loss=881.40331 Correct=99.23%
Testing: Correct=99.26%
Time: Training=9.4sec, Testing=0.4sec
MNIST with Adam, ReduceLROnPlateau, cross-entropy on GPU
Here a list of the changes:
Added to the beginning
assert torch.cuda.is_available() is True
device_gpu = torch.device("cuda:0")
Network after its creating moved to the GPU
network = torch.nn.Sequential([...]).to(device=device_gpu)
During training
output = network(train_processing_chain(image).to(device=device_gpu))
loss = loss_function(output, target.to(device_gpu))
train_loss += loss.item()
train_correct += (output.argmax(dim=1).cpu() == target).sum().numpy()
During testing
output = network(test_processing_chain(image).to(device=device_gpu))
test_correct += (output.argmax(dim=1).cpu() == target).sum().numpy()
Full source code:
import os
os.environ["TF_CPP_MIN_LOG_LEVEL"] = "3"
import torch
import torchvision # type:ignore
import numpy as np
import time
from torch.utils.tensorboard import SummaryWriter
assert torch.cuda.is_available() is True
device_gpu = torch.device("cuda:0")
class MyDataset(torch.utils.data.Dataset):
# Initialize
def __init__(self, train: bool = False) -> None:
super(MyDataset, self).__init__()
if train is True:
self.pattern_storage: np.ndarray = np.load("train_pattern_storage.npy")
self.label_storage: np.ndarray = np.load("train_label_storage.npy")
else:
self.pattern_storage = np.load("test_pattern_storage.npy")
self.label_storage = np.load("test_label_storage.npy")
self.pattern_storage = self.pattern_storage.astype(np.float32)
self.pattern_storage /= np.max(self.pattern_storage)
# How many pattern are there?
self.number_of_pattern: int = self.label_storage.shape[0]
def __len__(self) -> int:
return self.number_of_pattern
# Get one pattern at position index
def __getitem__(self, index: int) -> tuple[torch.Tensor, int]:
image = torch.tensor(self.pattern_storage[index, np.newaxis, :, :])
target = int(self.label_storage[index])
return image, target
# Some parameters
input_number_of_channel: int = 1
input_dim_x: int = 24
input_dim_y: int = 24
number_of_output_channels_conv1: int = 32
number_of_output_channels_conv2: int = 64
number_of_output_channels_flatten1: int = 576
number_of_output_channels_full1: int = 10
kernel_size_conv1: tuple[int, int] = (5, 5)
kernel_size_pool1: tuple[int, int] = (2, 2)
kernel_size_conv2: tuple[int, int] = (5, 5)
kernel_size_pool2: tuple[int, int] = (2, 2)
stride_conv1: tuple[int, int] = (1, 1)
stride_pool1: tuple[int, int] = (2, 2)
stride_conv2: tuple[int, int] = (1, 1)
stride_pool2: tuple[int, int] = (2, 2)
padding_conv1: int = 0
padding_pool1: int = 0
padding_conv2: int = 0
padding_pool2: int = 0
network = torch.nn.Sequential(
torch.nn.Conv2d(
in_channels=input_number_of_channel,
out_channels=number_of_output_channels_conv1,
kernel_size=kernel_size_conv1,
stride=stride_conv1,
padding=padding_conv1,
),
torch.nn.ReLU(),
torch.nn.MaxPool2d(
kernel_size=kernel_size_pool1, stride=stride_pool1, padding=padding_pool1
),
torch.nn.Conv2d(
in_channels=number_of_output_channels_conv1,
out_channels=number_of_output_channels_conv2,
kernel_size=kernel_size_conv2,
stride=stride_conv2,
padding=padding_conv2,
),
torch.nn.ReLU(),
torch.nn.MaxPool2d(
kernel_size=kernel_size_pool2, stride=stride_pool2, padding=padding_pool2
),
torch.nn.Flatten(
start_dim=1,
),
torch.nn.Linear(
in_features=number_of_output_channels_flatten1,
out_features=number_of_output_channels_full1,
bias=True,
),
torch.nn.Softmax(dim=1),
).to(device=device_gpu)
test_processing_chain = torchvision.transforms.Compose(
transforms=[torchvision.transforms.CenterCrop((24, 24))],
)
train_processing_chain = torchvision.transforms.Compose(
transforms=[torchvision.transforms.RandomCrop((24, 24))],
)
dataset_train = MyDataset(train=True)
dataset_test = MyDataset(train=False)
batch_size_train = 100
batch_size_test = 100
train_data_load = torch.utils.data.DataLoader(
dataset_train, batch_size=batch_size_train, shuffle=True
)
test_data_load = torch.utils.data.DataLoader(
dataset_test, batch_size=batch_size_test, shuffle=False
)
# -------------------------------------------
# The optimizer
optimizer = torch.optim.Adam(network.parameters(), lr=0.001)
# The LR Scheduler
lr_scheduler = torch.optim.lr_scheduler.ReduceLROnPlateau(optimizer)
number_of_test_pattern: int = dataset_test.__len__()
number_of_train_pattern: int = dataset_train.__len__()
number_of_epoch: int = 50
tb = SummaryWriter(log_dir="run")
loss_function = torch.nn.CrossEntropyLoss()
for epoch_id in range(0, number_of_epoch):
print(f"Epoch: {epoch_id}")
t_start: float = time.perf_counter()
train_loss: float = 0.0
train_correct: int = 0
train_number: int = 0
test_correct: int = 0
test_number: int = 0
# Switch the network into training mode
network.train()
# This runs in total for one epoch split up into mini-batches
for image, target in train_data_load:
# Clean the gradient
optimizer.zero_grad()
output = network(train_processing_chain(image).to(device=device_gpu))
loss = loss_function(output, target.to(device=device_gpu))
train_loss += loss.item()
train_correct += (output.argmax(dim=1).cpu() == target).sum().numpy()
train_number += target.shape[0]
# Calculate backprop
loss.backward()
# Update the parameter
optimizer.step()
# Update the learning rate
lr_scheduler.step(train_loss)
t_training: float = time.perf_counter()
# Switch the network into evalution mode
network.eval()
with torch.no_grad():
for image, target in test_data_load:
output = network(test_processing_chain(image).to(device=device_gpu))
test_correct += (output.argmax(dim=1).cpu() == target).sum().numpy()
test_number += target.shape[0]
t_testing = time.perf_counter()
perfomance_test_correct: float = 100.0 * test_correct / test_number
perfomance_train_correct: float = 100.0 * train_correct / train_number
tb.add_scalar("Train Loss", train_loss, epoch_id)
tb.add_scalar("Train Number Correct", train_correct, epoch_id)
tb.add_scalar("Test Number Correct", test_correct, epoch_id)
print(f"Training: Loss={train_loss:.5f} Correct={perfomance_train_correct:.2f}%")
print(f"Testing: Correct={perfomance_test_correct:.2f}%")
print(
f"Time: Training={(t_training-t_start):.1f}sec, Testing={(t_testing-t_training):.1f}sec"
)
torch.save(network, "Model_MNIST_A_" + str(epoch_id) + ".pt")
print()
tb.flush()
tb.close()
Mean square error
You might be inclined to use the MSE instead of the cross entropy.
But be aware that you need to change more than just the loss function from
loss_function = torch.nn.CrossEntropyLoss()
to
loss_function = torch.nn.MSELoss()
Why? Because the input changes from the correct class represented by an integer into a one hot encoded vector.
A fast way to do so is this function which uses in-place scatter
def class_to_one_hot(
correct_label: torch.Tensor, number_of_neurons: int
) -> torch.Tensor:
target_one_hot: torch.Tensor = torch.zeros(
(correct_label.shape[0], number_of_neurons)
)
target_one_hot.scatter_(
1, correct_label.unsqueeze(1), torch.ones((correct_label.shape[0], 1))
)
return target_one_hot
Obviously, we also need to modify this line
loss = loss_function(output, target)
to
loss = loss_function(
output, class_to_one_hot(target, number_of_output_channels_full1)
)
Full source:
import os
os.environ["TF_CPP_MIN_LOG_LEVEL"] = "3"
import torch
import torchvision # type:ignore
import numpy as np
import time
from torch.utils.tensorboard import SummaryWriter
def class_to_one_hot(
correct_label: torch.Tensor, number_of_neurons: int
) -> torch.Tensor:
target_one_hot: torch.Tensor = torch.zeros(
(correct_label.shape[0], number_of_neurons)
)
target_one_hot.scatter_(
1, correct_label.unsqueeze(1), torch.ones((correct_label.shape[0], 1))
)
return target_one_hot
assert torch.cuda.is_available() is True
device_gpu = torch.device("cuda:0")
class MyDataset(torch.utils.data.Dataset):
# Initialize
def __init__(self, train: bool = False) -> None:
super(MyDataset, self).__init__()
if train is True:
self.pattern_storage: np.ndarray = np.load("train_pattern_storage.npy")
self.label_storage: np.ndarray = np.load("train_label_storage.npy")
else:
self.pattern_storage = np.load("test_pattern_storage.npy")
self.label_storage = np.load("test_label_storage.npy")
self.pattern_storage = self.pattern_storage.astype(np.float32)
self.pattern_storage /= np.max(self.pattern_storage)
# How many pattern are there?
self.number_of_pattern: int = self.label_storage.shape[0]
def __len__(self) -> int:
return self.number_of_pattern
# Get one pattern at position index
def __getitem__(self, index: int) -> tuple[torch.Tensor, int]:
image = torch.tensor(self.pattern_storage[index, np.newaxis, :, :])
target = int(self.label_storage[index])
return image, target
# Some parameters
input_number_of_channel: int = 1
input_dim_x: int = 24
input_dim_y: int = 24
number_of_output_channels_conv1: int = 32
number_of_output_channels_conv2: int = 64
number_of_output_channels_flatten1: int = 576
number_of_output_channels_full1: int = 10
kernel_size_conv1: tuple[int, int] = (5, 5)
kernel_size_pool1: tuple[int, int] = (2, 2)
kernel_size_conv2: tuple[int, int] = (5, 5)
kernel_size_pool2: tuple[int, int] = (2, 2)
stride_conv1: tuple[int, int] = (1, 1)
stride_pool1: tuple[int, int] = (2, 2)
stride_conv2: tuple[int, int] = (1, 1)
stride_pool2: tuple[int, int] = (2, 2)
padding_conv1: int = 0
padding_pool1: int = 0
padding_conv2: int = 0
padding_pool2: int = 0
network = torch.nn.Sequential(
torch.nn.Conv2d(
in_channels=input_number_of_channel,
out_channels=number_of_output_channels_conv1,
kernel_size=kernel_size_conv1,
stride=stride_conv1,
padding=padding_conv1,
),
torch.nn.ReLU(),
torch.nn.MaxPool2d(
kernel_size=kernel_size_pool1, stride=stride_pool1, padding=padding_pool1
),
torch.nn.Conv2d(
in_channels=number_of_output_channels_conv1,
out_channels=number_of_output_channels_conv2,
kernel_size=kernel_size_conv2,
stride=stride_conv2,
padding=padding_conv2,
),
torch.nn.ReLU(),
torch.nn.MaxPool2d(
kernel_size=kernel_size_pool2, stride=stride_pool2, padding=padding_pool2
),
torch.nn.Flatten(
start_dim=1,
),
torch.nn.Linear(
in_features=number_of_output_channels_flatten1,
out_features=number_of_output_channels_full1,
bias=True,
),
torch.nn.Softmax(dim=1),
).to(device=device_gpu)
test_processing_chain = torchvision.transforms.Compose(
transforms=[torchvision.transforms.CenterCrop((24, 24))],
)
train_processing_chain = torchvision.transforms.Compose(
transforms=[torchvision.transforms.RandomCrop((24, 24))],
)
dataset_train = MyDataset(train=True)
dataset_test = MyDataset(train=False)
batch_size_train = 100
batch_size_test = 100
train_data_load = torch.utils.data.DataLoader(
dataset_train, batch_size=batch_size_train, shuffle=True
)
test_data_load = torch.utils.data.DataLoader(
dataset_test, batch_size=batch_size_test, shuffle=False
)
# -------------------------------------------
# The optimizer
optimizer = torch.optim.Adam(network.parameters(), lr=0.001)
# The LR Scheduler
lr_scheduler = torch.optim.lr_scheduler.ReduceLROnPlateau(optimizer)
number_of_test_pattern: int = dataset_test.__len__()
number_of_train_pattern: int = dataset_train.__len__()
number_of_epoch: int = 50
tb = SummaryWriter(log_dir="run")
loss_function = torch.nn.MSELoss()
for epoch_id in range(0, number_of_epoch):
print(f"Epoch: {epoch_id}")
t_start: float = time.perf_counter()
train_loss: float = 0.0
train_correct: int = 0
train_number: int = 0
test_correct: int = 0
test_number: int = 0
# Switch the network into training mode
network.train()
# This runs in total for one epoch split up into mini-batches
for image, target in train_data_load:
# Clean the gradient
optimizer.zero_grad()
output = network(train_processing_chain(image).to(device=device_gpu))
loss = loss_function(
output,
class_to_one_hot(target, number_of_output_channels_full1).to(
device=device_gpu
),
)
train_loss += loss.item()
train_correct += (output.argmax(dim=1).cpu() == target).sum().numpy()
train_number += target.shape[0]
# Calculate backprop
loss.backward()
# Update the parameter
optimizer.step()
# Update the learning rate
lr_scheduler.step(train_loss)
t_training: float = time.perf_counter()
# Switch the network into evalution mode
network.eval()
with torch.no_grad():
for image, target in test_data_load:
output = network(test_processing_chain(image).to(device=device_gpu))
test_correct += (output.argmax(dim=1).cpu() == target).sum().numpy()
test_number += target.shape[0]
t_testing = time.perf_counter()
perfomance_test_correct: float = 100.0 * test_correct / test_number
perfomance_train_correct: float = 100.0 * train_correct / train_number
tb.add_scalar("Train Loss", train_loss, epoch_id)
tb.add_scalar("Train Number Correct", train_correct, epoch_id)
tb.add_scalar("Test Number Correct", test_correct, epoch_id)
print(f"Training: Loss={train_loss:.5f} Correct={perfomance_train_correct:.2f}%")
print(f"Testing: Correct={perfomance_test_correct:.2f}%")
print(
f"Time: Training={(t_training-t_start):.1f}sec, Testing={(t_testing-t_training):.1f}sec"
)
torch.save(network, "Model_MNIST_A_" + str(epoch_id) + ".pt")
print()
tb.flush()
tb.close()
The source code is Open Source and can be found on GitHub.